Publications
(*) denotes equal contribution
2026
-
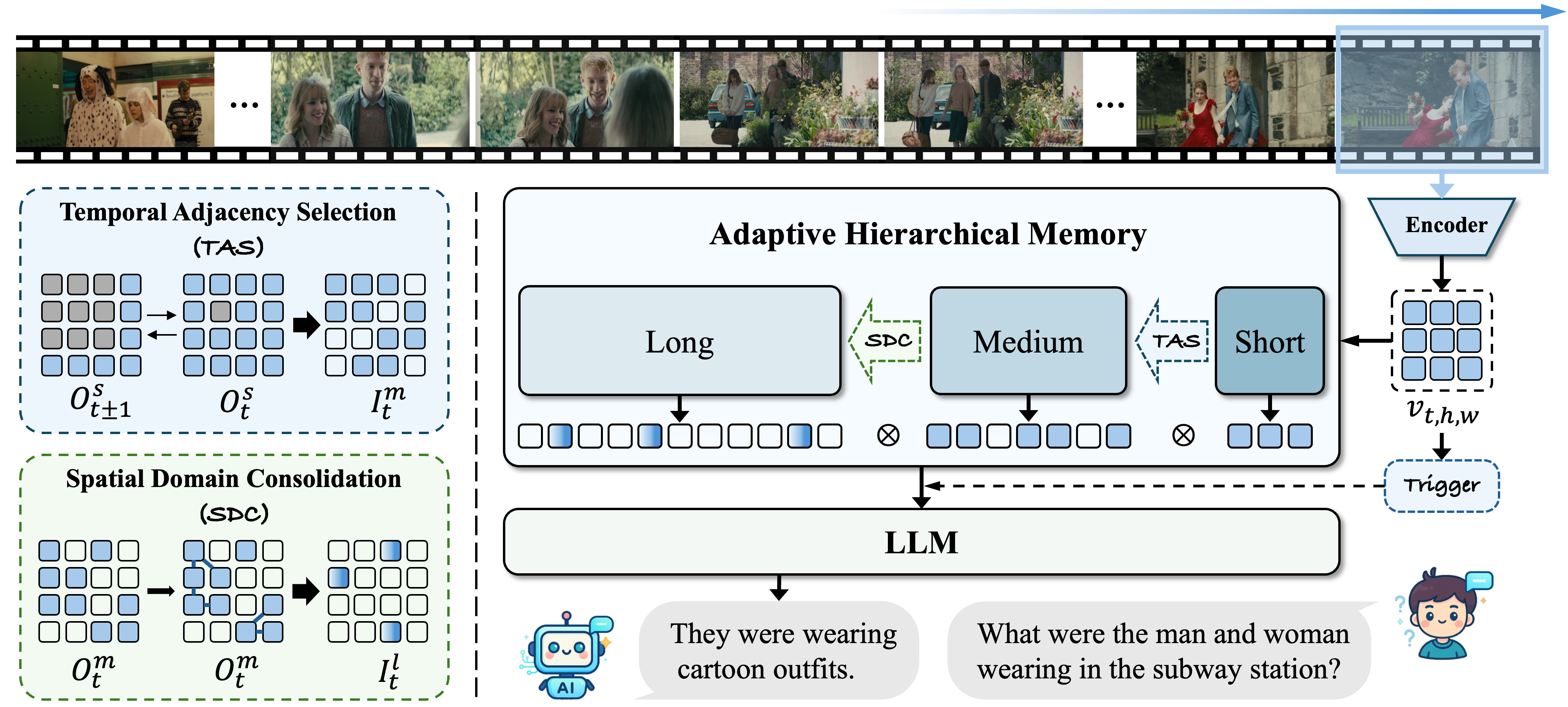 FluxMem: Adaptive Hierarchical Memory for Streaming Video UnderstandingCVPR, 2026
FluxMem: Adaptive Hierarchical Memory for Streaming Video UnderstandingCVPR, 2026This paper presents FluxMem, a training-free framework for efficient streaming video understanding. FluxMem adaptively compresses redundant visual memory through a hierarchical, two-stage design: (1) a Temporal Adjacency Selection (TAS) module removes redundant visual tokens across adjacent frames, and (2) a Spatial Domain Consolidation (SDC) module further merges spatially repetitive regions within each frame into compact representations. To adapt effectively to dynamic scenes, we introduce a self-adaptive token compression mechanism in both TAS and SDC, which automatically determines the compression rate based on intrinsic scene statistics rather than manual tuning. Extensive experiments demonstrate that FluxMem achieves new state-of-the-art results on existing online video benchmarks, reaching 76.4 on StreamingBench and 66.3 on OVO-Bench under real-time settings. Furthermore, it maintains strong offline performance, achieving 73.1 M-Avg on MLVU while using 65% fewer visual tokens.
@article{xie2026fluxmem, title = {FluxMem: Adaptive Hierarchical Memory for Streaming Video Understanding}, author = {Xie, Yiweng and He, Bo and Wang, Junke and Zheng, Xiangyu and Ye, Ziyi and Wu, Zuxuan}, journal = {CVPR}, year = {2026}, }
2025
-
 NeurIPS, 2025
NeurIPS, 2025Large Multimodal Models (LMMs) have made significant breakthroughs with the advancement of instruction tuning. However, while existing models can understand images and videos at a holistic level, they still struggle with instance-level understanding that requires a more nuanced comprehension and alignment. Instance-level understanding is crucial, as it focuses on the specific elements that we are most interested in. Excitingly, existing works find that the SOTA LMMs exhibit strong instance understanding capabilities when provided with explicit visual cues. Motivated by this, we introduce an automated annotation pipeline assisted by GPT-4o to extract instance-level information from images and videos through explicit visual prompting for instance guidance. Building upon this pipeline, we proposed Inst-IT, a solution to enhance LMMs’ Instance understanding via explicit visual prompt Instruction Tuning. Inst-IT consists of a benchmark to diagnose multimodal instance-level understanding, a large-scale instruction-tuning dataset, and a continuous instruction-tuning training paradigm to effectively enhance spatial-temporal instance understanding capabilities of existing LMMs. Experimental results show that our models not only achieve outstanding performance on Inst-IT Bench but also demonstrate significant improvements on other generic image and video understanding benchmarks, such as AI2D and Egoschema. This highlights that our dataset not only boosts instance-level understanding but also strengthens the overall capabilities of generic image and video comprehension.
@article{peng2024boosting, title = {Inst-IT: Boosting Multimodal Instance Understanding via Explicit Visual Prompt Instruction Tuning}, author = {Peng*, Wujian and Meng*, Lingchen and Chen, Yitong and Xie, Yiweng and Liu, Yang and Gui, Tao and Hang, Xu and Qiu, Xipeng and Wu, Zuxuan and Jiang, Yu-Gang}, journal = {NeurIPS}, year = {2025}, url = {https://arxiv.org/abs/2412.03565}, }
2023
-
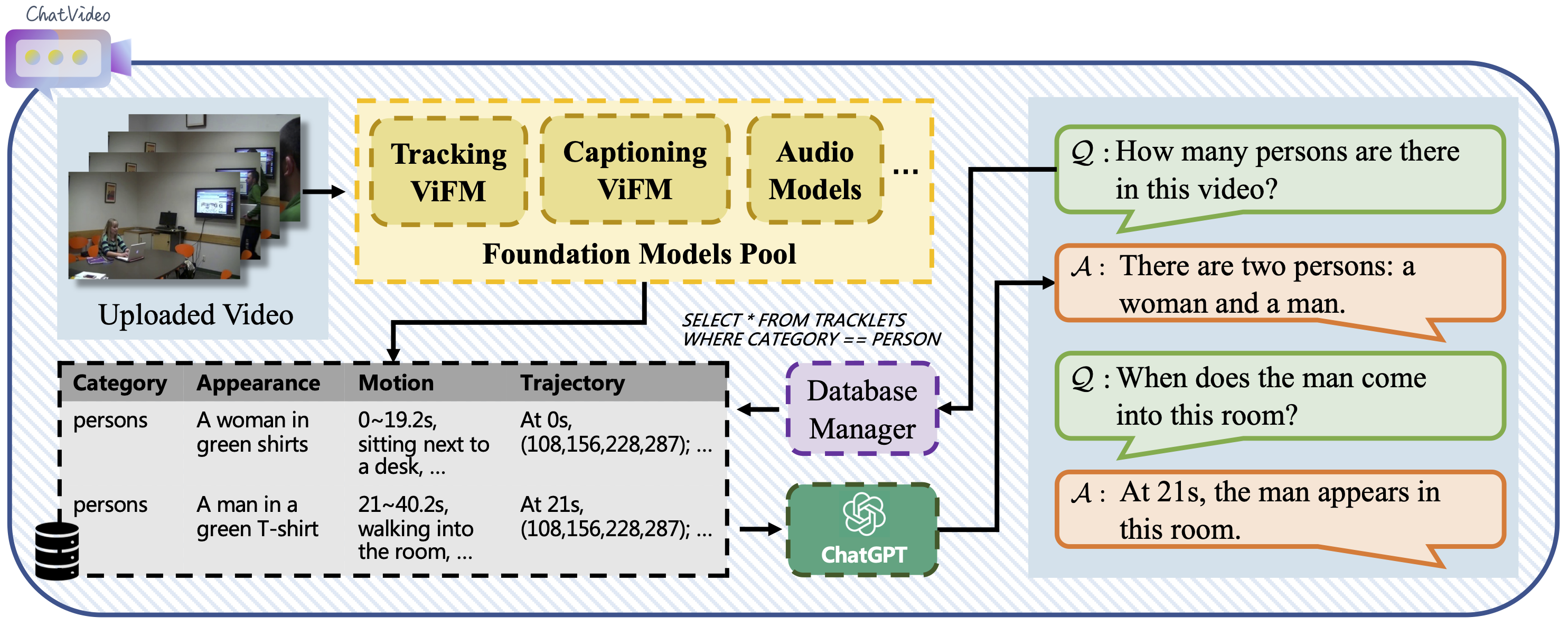 Junke Wang, Dongdong Chen, Yiweng Xie, Chong Luo, and 4 more authorsarXiv preprint, 2023
Junke Wang, Dongdong Chen, Yiweng Xie, Chong Luo, and 4 more authorsarXiv preprint, 2023Existing deep video models are limited by specific tasks, fixed input-output spaces, and poor generalization capabilities, making it difficult to deploy them in real-world scenarios. In this paper, we present our vision for multimodal and versatile video understanding and propose a prototype system, ChatVideo. Our system is built upon a tracklet-centric paradigm, which treats tracklets as the basic video unit and employs various Video Foundation Models (ViFMs) to annotate their properties (e.g., appearance, motion, etc.). All the detected tracklets are stored in a database and interact with the user through a database manager. We have conducted extensive case studies on different types of in-the-wild videos, which demonstrates the effectiveness of our method in answering various video-related problems.
@article{wang2023chatvideo, title = {ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System}, author = {Wang, Junke and Chen, Dongdong and Xie, Yiweng and Luo, Chong and Dai, Xiyang and Yuan, Lu and Wu, Zuxuan and Jiang, Yu-Gang}, journal = {arXiv preprint}, year = {2023}, url = {https://arxiv.org/abs/2304.14407}, }