I am currently a second year M.S. student in the School of Computer Science at Fudan University, supervised by Prof. Zuxuan Wu. Before that, I received my B.S. degree in Computer Science from Fudan University in 2024.
My research interests lie in computer vision. I am particularly interested in multimodal large language models, video understanding, and embodied intelligence.
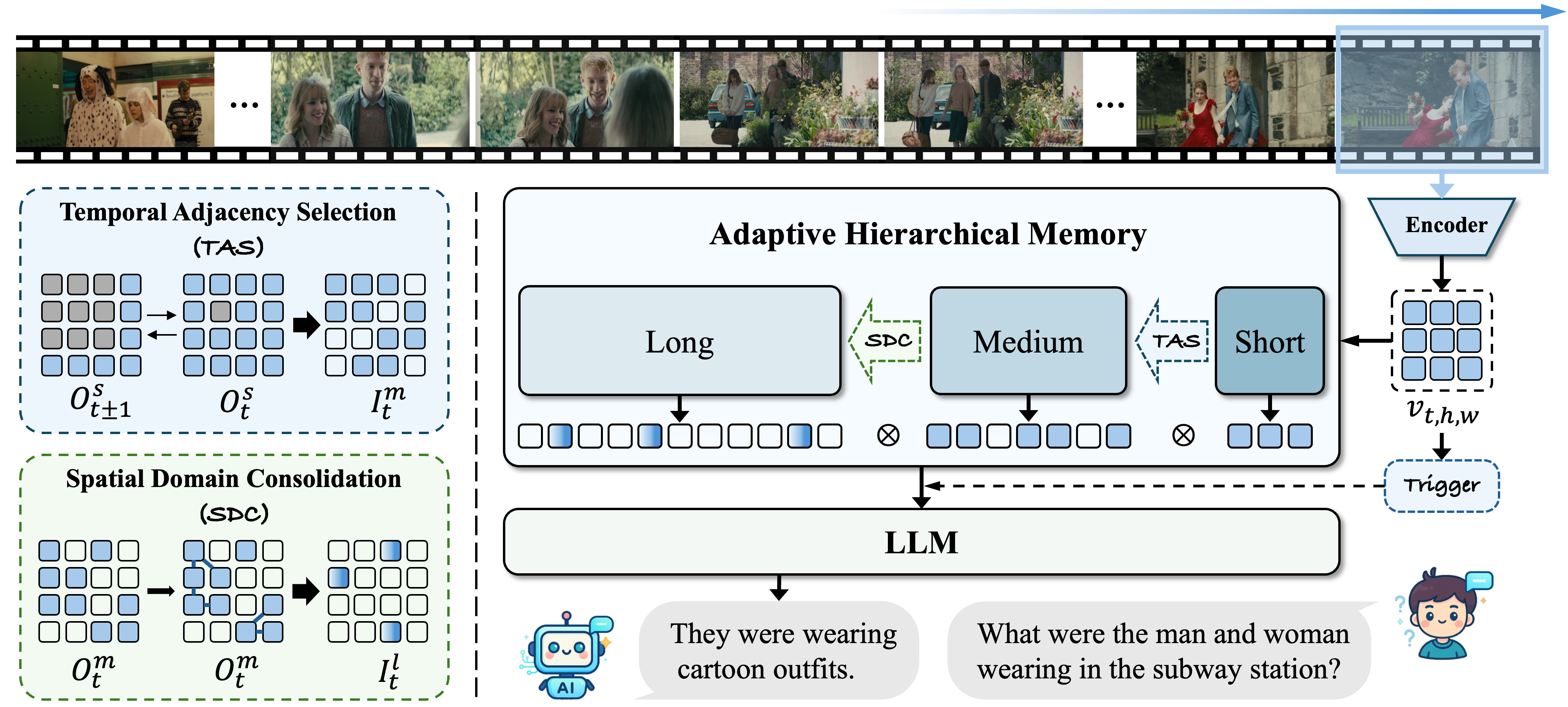
This paper presents FluxMem, a training-free framework for efficient streaming video understanding. FluxMem adaptively compresses redundant visual memory through a hierarchical, two-stage design: (1) a Temporal Adjacency Selection (TAS) module removes redundant visual tokens across adjacent frames, and (2) a Spatial Domain Consolidation (SDC) module further merges spatially repetitive regions within each frame into compact representations. To adapt effectively to dynamic scenes, we introduce a self-adaptive token compression mechanism in both TAS and SDC, which automatically determines the compression rate based on intrinsic scene statistics rather than manual tuning. Extensive experiments demonstrate that FluxMem achieves new state-of-the-art results on existing online video benchmarks, reaching 76.4 on StreamingBench and 66.3 on OVO-Bench under real-time settings. Furthermore, it maintains strong offline performance, achieving 73.1 M-Avg on MLVU while using 65% fewer visual tokens.
@article{xie2026fluxmem,title={FluxMem: Adaptive Hierarchical Memory for Streaming Video Understanding},author={Xie, Yiweng and He, Bo and Wang, Junke and Zheng, Xiangyu and Ye, Ziyi and Wu, Zuxuan},journal={arXiv preprint},year={2025},url={https://arxiv.org/abs/},selected=true}